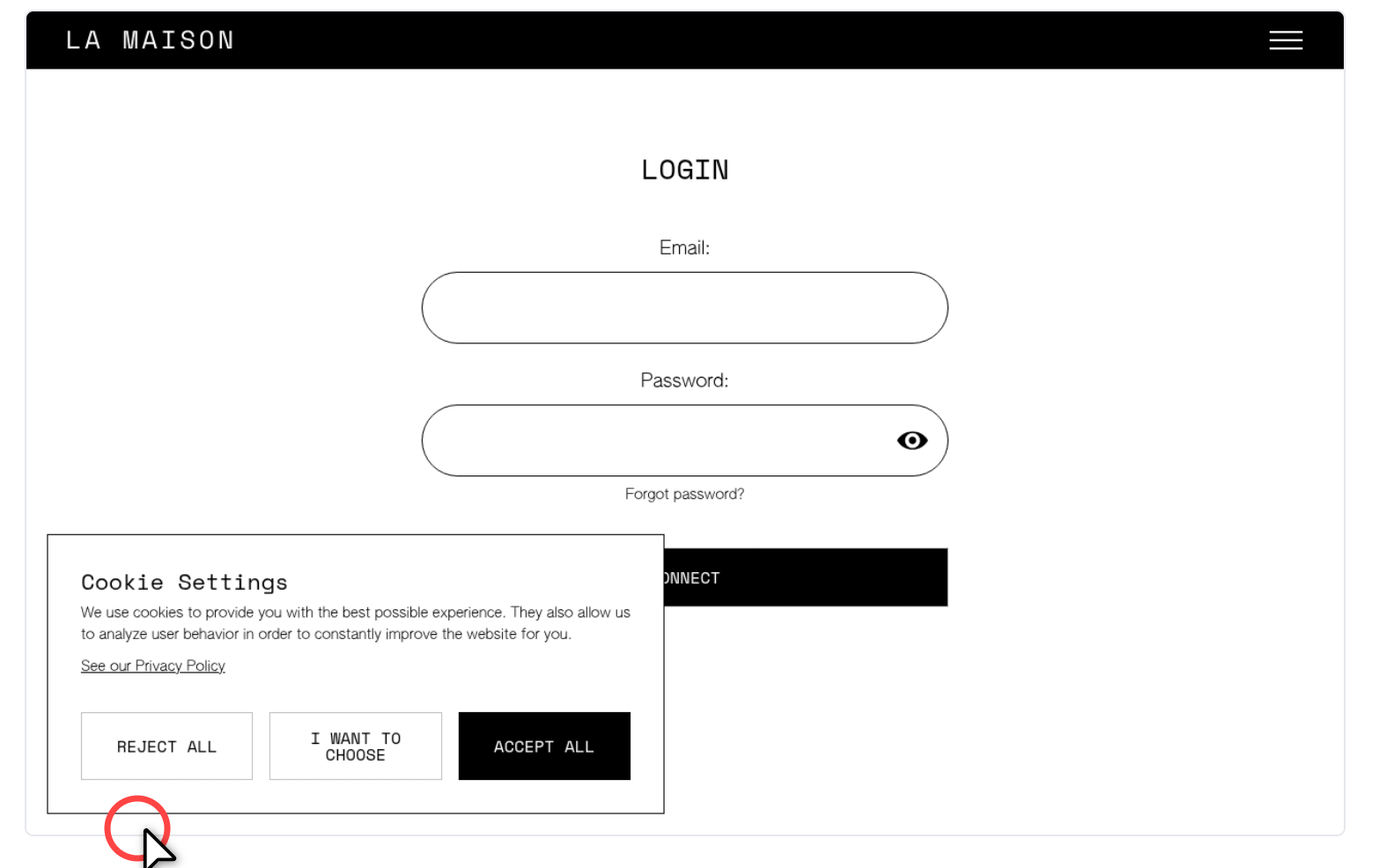
Computer-use agents often make localization mistakes, that is, they output the correct reasoning about where to click but still pick the wrong coordinates. Although there are some techniques to get around it, they generally come with downsides. For instance, some rely on mixing data from the DOM, such as for drawing bounding boxes, which rely on low-accuracy heuristics and can hurt latency
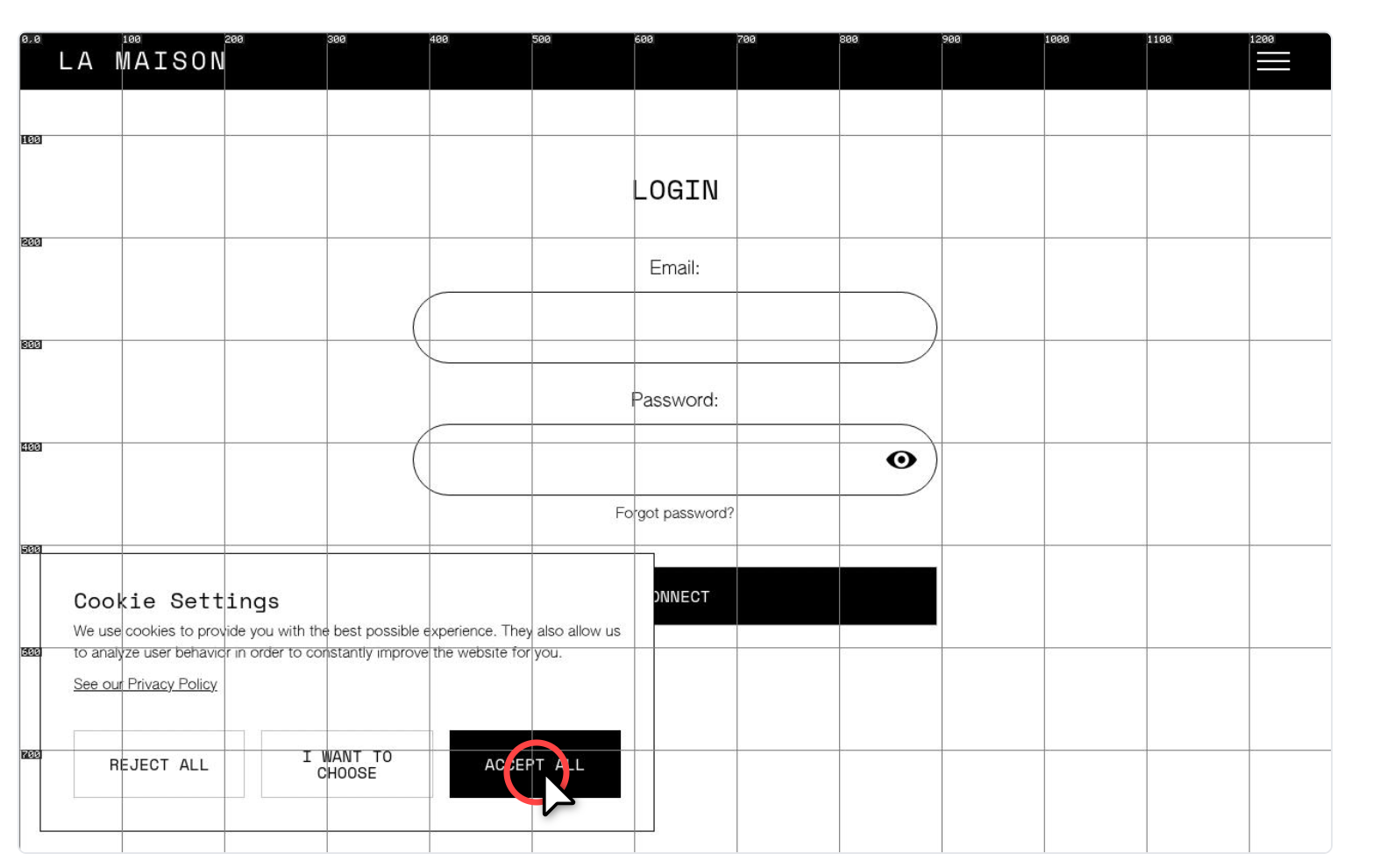
We've been using a purely visual technique that is very effective at correcting localization mistakes, which is essentially to give the model a tool to enable or disable a grid overlay on the image, with markers for the coordinates, as below, and prompting it to enable this grid when it's having issues interacting with a certain element
In most cases the model realizes that it's clicking on the wrong spot, enables the tool, and then figures out the right coordinates, which solves almost all localization issues we used to see. Naturally one may question why not overlay a grid all the time, if it's so effective. But the issue is that the grid can confuse the model in other scenarios, in particular in high-density screenshots (eg, a lot of text, spreadsheets), capping its capability to apprehend content
As to why localization issues happen in the first place, with models that are otherwise so capable, I think there's probably some data imbalance between the training data that's available for the different screenshot resolutions. As in, if consent screens appear more often in 1280x960 screenshots than in 800x600 ones, then when running inference over a screenshot presenting a consent screen in 800x600 resolution its prediction for the coordinates will pass through latent spaces biased towards the 1280x960 screenshot